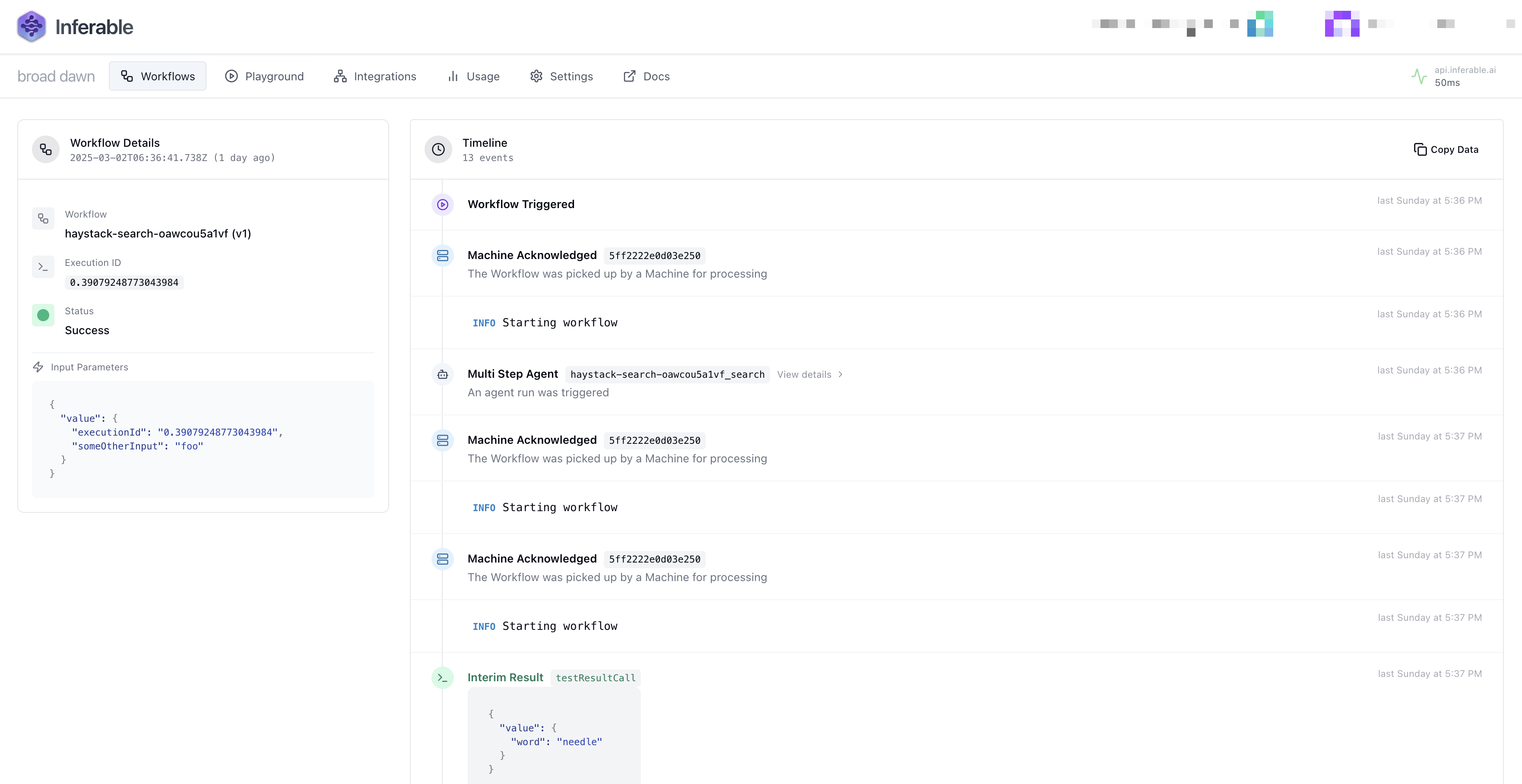
Most AI orchestration frameworks are built with the assumption that model calls and function execution happen within the same process. This approach, while straightforward, introduces several limitations when building production-grade AI applications quickly. Inferable takes a fundamentally different approach with its distributed control plane architecture.Documentation Index
Fetch the complete documentation index at: https://docs.inferable.ai/llms.txt
Use this file to discover all available pages before exploring further.
The Control Plane
The control plane is the central component of Inferable, responsible for orchestrating the execution of workflows and managing their state. A cloud version of it is hosted and maintained by Inferable at api.inferable.ai. It’s a stateful API server with a persistent storage layer for workflow state.Traditional Agent Framework Limitations
Co-located Execution Model
In traditional agent frameworks:- Single Process Dependency: Model calls and function execution happen in the same runtime, creating a single point of failure
- Limited Scalability: Resource constraints of a single process limit the complexity and number of parallel operations
- Durability Challenges: Maintaining workflow state across restarts requires additional infrastructure
- Custom Persistence Solutions: Developers must implement their own persistence layer for workflow durability
Bring-Your-Own-Persistence Issues
Some frameworks attempt to address durability by allowing developers to bring their own persistence layer:- Implementation Burden: Forces developers to design, implement, and maintain state management systems
- Complexity Overhead: Adds significant complexity to application architecture
- Inconsistent Recovery: Often leads to incomplete or inconsistent recovery mechanisms
- Development Time Cost: Increases development time with non-core functionality
Distributed Architecture with Long Polling
Inferable’s control plane architecture enables workflows to run in isolated environments, including private VPCs, while maintaining communication with the central control plane through long polling.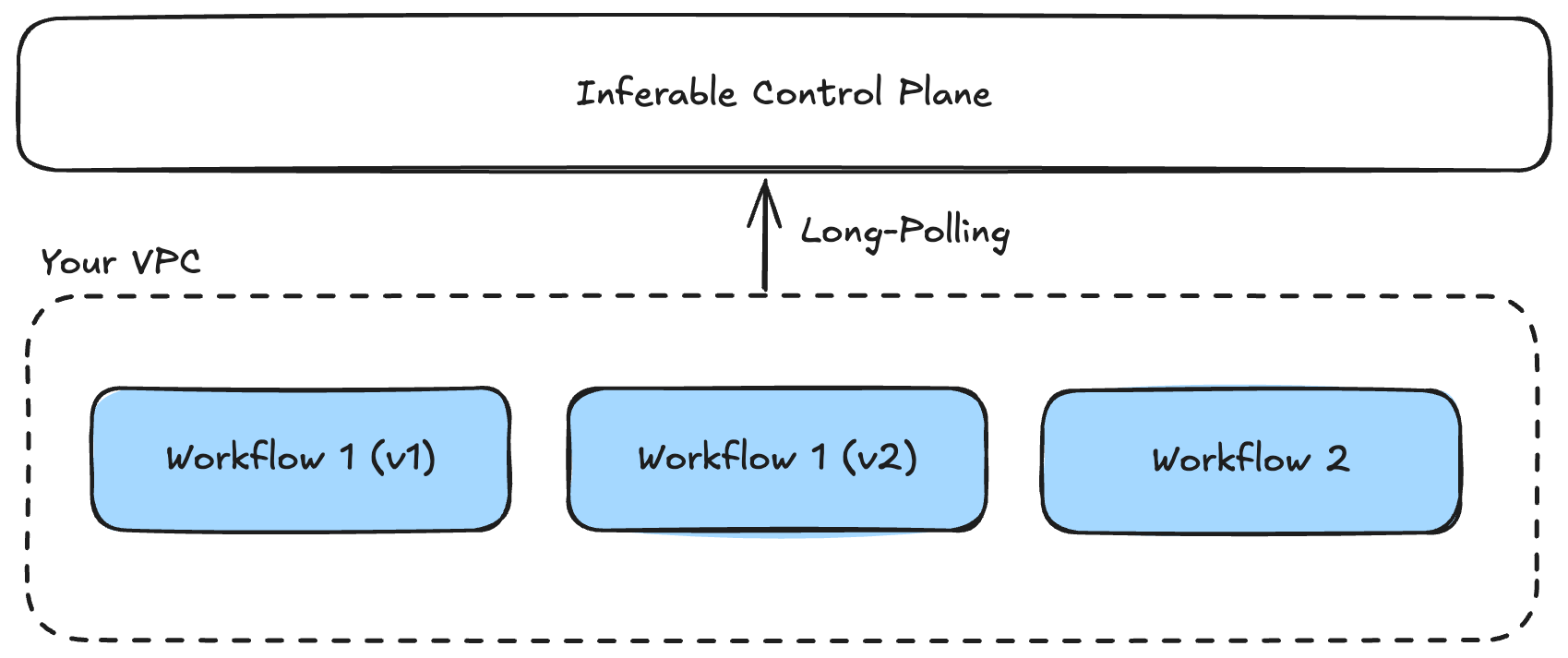
Distributed Architecture
- Separation of Concerns: Clear separation between orchestration (handled by the control plane) and code execution (in your environment)
- Optimized Resource Allocation: Workflows can be paused and resumed on different machines, and control-plane handles the routing and load balancing
- Fault Isolation: Transient issues in any single machine don’t affect the stability of the overall workflow
- Workflow Versioning: Control plane maintains workflow version affinity and allows for easy updates to the workflow definition
Built-in Durability
- Persistent State Management: The control plane automatically persists the entire workflow state without developer intervention
- Transaction-based Execution: All state changes are handled through transactional operations, ensuring consistency
- Zero Loss Recovery: Workflows can recover from exactly where they left off, even after extended outages
True Workflow Pausing
Inferable’s control plane enables genuine workflow pausing:- Indefinite Pausing: Workflows can be paused for any duration, from seconds to months
- Contextual State Preservation: The complete workflow context is preserved during pauses
- Human-in-the-Loop Integration: Pausing workflows for approvals and human intervention
- Resume with Full Context: Workflows resume with full access to their pre-pause state and context
Benefits
Pausing and Resuming for Human-in-the-Loop Workflows
Inferable’s architecture shines in scenarios requiring human approval:- The workflow pauses when approval is needed
- The control plane maintains the complete execution state
- After approval (which could be hours or days later), execution resumes exactly where it left off
- No custom state management code is required
Long-Running Processes
If you’re doing long running LLM-based workflows, like a large batch processing job that takes hours or an agent execution that takes minutes, you can pause the workflow at any point and resume from the same point later. The control plane will:- Maintain the workflow state for the entire duration
- Handle any intermittent issues with the execution
- Resume from the appropriate point if there are interruptions
- Provide visibility into the workflow status throughout its lifecycle in the Inferable app
Recovery from Failures
When machine or network failures occur: The control plane:- Detects machine failures through heartbeat mechanisms
- Redirects function calls to healthy machines
- Preserves the workflow state throughout the recovery process
- Continues execution from the point of failure
Global Observability
With a centralized control plane:- Cross-Function Tracing: Trace execution across multiple functions and services
- End-to-End Visibility: See the complete flow from initial prompt to final result
- Unified Logging: All workflow activities are logged in a consistent format
- Centralized Monitoring: Monitor all workflows from a single dashboard